

Ultimele update-uri Google, în special update-ul general din 12 Martie, au venit cu multe schimbări de abordare, funcționare și înțelegere a celui mai popular motor de căutare în România. Schimbarea majoră nu este una misterioasă sau neașteptată: suntem familiarizați deja de ceva vreme cu orientarea Google către utilizator (User Experience), inteligența artificială și mașina de învățare Google.
Update-urile Google - fie ele mai mari sau mai mici, generale sau concentrate pe un anumit aspect, precum conținutul, backlink-urile sau spamul - au efect asupra aspectelor tehnice și asupra conținutului unui website. Când vorbim de optimizarea și promovarea unui website, trebuie să ținem cont în egală măsură de aceste 2 aspecte, pentru că ambele au un impact puternic asupra indexării și ranking-ului. Prin urmare, să aruncăm o privire asupra modificărilor care au apărut în cazul ambelor aspecte, pentru a descoperi care sunt noile tendințe:
1. Aspectele tehnice
Google a reconfirmat recent câteva aspecte tehnice legate de indexarea paginilor unui site în baza de date a motorului de căutare. Am testat chiar noi aceste detalii și le-am verificat pe diferite tipuri de site-uri (magazine online, site-uri de prezentare sau de servicii), pentru a vedea cum funcționează:
- Tag-urile pentru paginație (rel=next și rel=prev) nu mai funcționează de câțiva ani și nu mai sunt factori de indexare. ( „not supported”);
- Tag-ul CANONICAL nu este interpretat de roboți ca fiind un semnal să nu indexeze o anumită pagină web; aceștia pot acum relaționa pagina web cu o alta, pe care o consideră mai potrivită sau, pur și simplu, pot ignora tag-ul din codul sursă, indexând pagina;
- În indexul Google au apărut pagini web care au fost restricționate la indexare în Robots.txt (acest lucru se face prin linia de cod Disallow: /) și care au un tag integrat în codul sursă, de tipul <meta name="robots" content="noindex, nofollow" />.
Motivul? Fie avem de-a face cu un bug al motorului de căutare, fie aceste comenzi de restricționare la indexare nu mai funcționează („not supported”).
Care sunt consecințele update-urilor tehnice:
- S-au indexat pagini pe care le-am construit de-a lungul timpului pentru campanii punctuale de marketing si pe care le-am marcat cu CANONICAL sau NO INDEX, dar nu le-am eliminat din site;
- S-au indexat și au fost listate în primele poziții/pagini de rezultate Google versiuni mai vechi ale site-ului, care au rămas “agățate” în website. Nu luasem în calcul faptul că ne-ar putea afecta, deoarece le restricționasem la indexare din Robots.txt;
- S-au indexat pagini generate de filtrarea produselor și de ordonarea acestora după diferite criterii (preț, cele mai vândute, cele mai noi, ordinea alfabetică etc.), pe care le-am marcat cu un tag CANONICAL pe URL-ul principal;
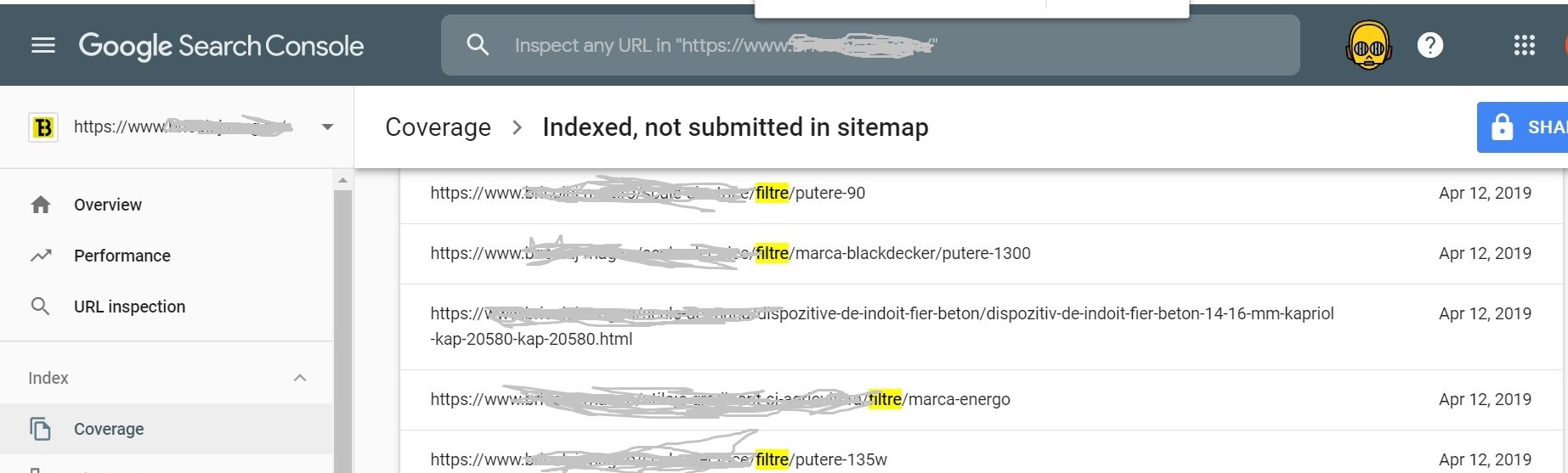
- În urma update-ului din 12 martie 2019, am văzut, la foarte multe site-uri, magazine online [în special website-uri de tip YMYL (Your Money or Your Life)], un volum mai mare de afișări în Search Console (ca urmare a indexării paginilor web care erau – de principiu - considerate restricționate la indexare), corelat cu o scădere a volumului de click-uri și a CTR-ului.
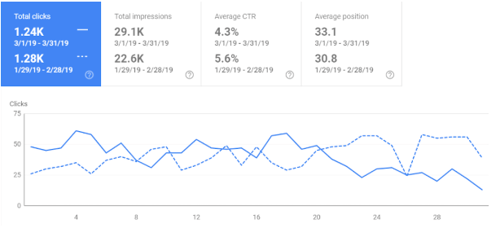 Putem interpreta din următorul grafic comparativ, generat în Search Console pentru un magazin online, faptul că această creștere artificială și bruscă a volumului de pagini indexate a avut ca revers scăderea calității conținutului și a relevanței site-ului în ansamblu.
Putem interpreta din următorul grafic comparativ, generat în Search Console pentru un magazin online, faptul că această creștere artificială și bruscă a volumului de pagini indexate a avut ca revers scăderea calității conținutului și a relevanței site-ului în ansamblu.
Cât de tare s-a zguduit online-ul la update-ul
Google din 12 martie
2. Aspectele ce țin de conținut – tipuri de pagini de conținut în website și cum le gestionăm
Trecem în continuare de la partea tehnică la cea care ține de conținutul propriu-zis. Astfel, un website care are o vechime de cel puțin 1 an a adunat în tot acest timp în structura sa pagini de diferite tipuri, care trebuie monitorizate și gestionate cu grijă.
Așa cum am văzut deja mai sus, roboții citesc și indexează aproape tot ce găsesc pe serverul pe care este găzduit domeniul web / site-ul, fie că sunt pagini relevante pentru domeniul de activitate al site-ului, fie că sunt pagini dedicate unor campanii de promovare de scurtă durată, pagini generate de filtre, etc.
Din acest motiv, trebuie să știm ce pagini avem în site, ce conținut avem în ele și, mai ales, ce face Google cu ele. Le putem clasifica în câteva categorii simple și intuitive:
- Pagini de informații generale: homepage-ul, pagina cu informații despre noi, detaliile legate de cum cumpără și comandă clienții, care sunt termenii și condițiile, care sunt datele de contact etc.);
- Pagini de categorii și subcategorii de produse sau de servicii;
- Pagini de produse sau de servicii;
- Pagini de conținut sau de mesaj, cum ar fi site-urile de stiri sau blogurile;
- Pagini dedicate unor campanii punctuale de marketing;
- Pagini generate de filtre / ordonări ale produselor pe diferite criterii;
- Pagini de interacțiune sau pentru o funcționalitate, de unde descărcăm un e-book, trimitem un formular sau un sondaj de opinie. Acestea sunt cele care pot să genereze pagini duplicate la fiecare interacțiune a utilizatorilor.
Cele 7 tipuri de pagini de mai sus, ce constituie un website în ansamblul său, trebuie urmărite și gestionate cu atenție, astfel încât volumul de pagini irelevante să nu depășească volumul de pagini de conținut relevant.
Cum controlăm fluxul de pagini și structura site-ului:
- În cazul paginilor din categoriile 2, 3 și 4, dacă acestea au conținut foarte asemănător sau identic, fie îl modificăm - pentru a fi diferit, unic și original, fie renunțăm la duplicate, redirecționând paginile duplicate către pagina principală pentru conținutul respectiv;
- Dacă avem pagini care fac parte din structura piramidală a site-ului, dar nu au conținut sub formă de text sau au conținut irelevant, fie le adăugăm text relevant, original și de calitate, fie renunțăm la aceste pagini, redirecționându-le către o pagină relevantă din site (redirect permanent 301);
- Pentru paginile din categoria 5, realizate pentru campanii punctuale de marketing, este foarte important să le dezactivăm imediat ce s-a încheiat campania, cu redirect 301 către homepage sau o altă pagină din site;
- Paginile din categoria 6 sunt cele care pot să afecteze cel mai mult calitatea și relevanța unui website. Din acest motiv, este recomandat să evităm filtrele și criteriile de ordonare inutile cu care vin la pachet CMS-urile ecommerce de tip Open Source și care generează un volum mare de pagini de tip spam.
Explicația e simplă: așa cum spuneam mai sus, roboții citesc și indexează acum și paginile care au un tag CANONICAL sau o comandă NO INDEX în codul sursă. Reducerea la minimum a acestui tip de pagini, controlul modului în care se generează și ponderea lor în structura site-ului - în raport cu paginile din categoriile 1-4 - pot face diferența între un ranking foarte bun și performanțe foarte slabe ale site-ului în întregime; - Paginile web din categoria 7 ar trebui să aibă conținut de tip text și imagine optimizat, chiar dacă ele au un rol strict tehnic. Când acestea nu mai sunt utile sau de actualitate, fie trebuie redirecționate către o altă pagină din site, fie ar trebui actualizat conținutul. A doua variantă e cea mai bună, dacă URL-ul este general și permite un alt conținut în pagină.
Care sunt concluziile cu care ar trebui să rămânem?
Ultimele update-uri Google sunt o reconfirmare a orientării algoritmilor de indexare și ranking către utilizatori. Astfel, utilizatorul este principalul factor de ordonare în paginile de rezultate Google, iar update-urile motorului de căutare vin să actualizeze periodic ce a mai învățat inteligența artificială de la utilizatorii săi umani.
Din acest motiv, trebuie să ne concentrăm pe ce facem și cum facem pe site-urile noastre. Nu este suficient să realizăm conținut de foarte bună calitate, atâta timp cât site-ul este sufocat de un volum mare de pagini de tipul 5 – 6 – 7, la fel cum nu este suficient să avem un website cu o structură curată și clară, fără pagini duplicate sau goale, dacă nu avem conținut relevant și de foarte bună calitate.
Surse:
.png?width=300&height=450&name=banner%20ebook%202026%202%20(1).png)
